
Google スプレッドシートで、サイトURLをコピペしていったら、そのURLのサイトタイトル(title)・ページ説明(description)・noindex設定などが一覧になったものが欲しくなったのでその作り方をメモがてら紹介したいと思います!
スプレッドシートでWebページをスクレイピングできる記述方法

基本的に IMPORTXML という関数でページにアクセスし抽出をすることができます。
ページタイトル( title )の抽出
=INDEX(IMPORTXML(B2,"//title"),1,1)【B2】の部分はセルを指定してください。
B2セルにはURLが入力されている想定です。
XMPORTXML 関数で titleタグの文字列を抽出します。
そして、INDEX 関数で、最初の titleタグを抽出しています。
SVGを埋め込んで作られたサイトとかだと、titleタグが複数あるため、INDEX関数を使用したほうがいいです。
ページ説明( description )の抽出
=IFNA(IMPORTXML(B2,"//meta[@name='description']/@content"),"- 指定なし -")【B2】の部分はセルを指定してください。
B2セルにはURLが入力されている想定です。
IMPORTXML 関数で descriptionの値を抽出します。
IFNA 関数で、データがうまく出力されない場合は、「- 指定なし -」と出力するようにしました。
キーワード( keywords )の抽出
=IFNA(IMPORTXML(B2,"//meta[@name='keywords']/@content"),"- 指定なし -")【B2】の部分はセルを指定してください。
B2セルにはURLが入力されている想定です。
IMPORTXML 関数で keywords の値を抽出します。
IFNA 関数で、データがうまく出力されない場合は、「- 指定なし -」と出力するようにしました。
index設定の抽出
=IFNA(IMPORTXML(B2,"//meta[@name='robots']/@content"),"- 指定なし -")【B2】の部分はセルを指定してください。
B2セルにはURLが入力されている想定です。
IMPORTXML 関数で index設定の robots の値を抽出します。
IFNA 関数で、データがうまく出力されない場合は、「- 指定なし -」と出力するようにしました。
他にも独自で抽出したい場合
IMPORTXML関数の第1引数に URLを指定し、第2引数にパス(XPath)を指定します。
XPath の指定する値を調べる方法
Xpathは chromeブラウザを使用すれば簡単に調べることができます。
デベロッパーツールを開く
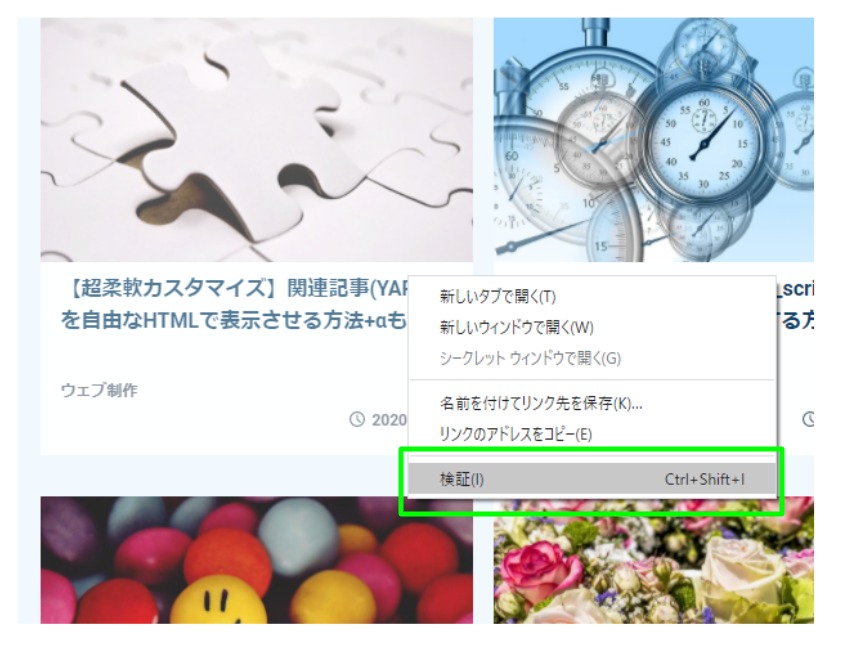
右クリックで、【検証】を選択し、デベロッパーツールを開きます。
XPathをコピー

デベロッパーツールのソースコード表示で、
- 取得したいタグ上で、右クリック
- 『Copy』の中の…
- 『Copy full XPath』を選択するとXPathをコピーできます。
このコピーしたXPathを、IMPORTXML関数の第2引数に指定することで指定できます。属性を取得したい場合は、 今回紹介した、descriptionの取得方法などを見本に指定すれば取得できます。
まとめ
スプレッドシートであまり難しいことをすると、重くなったりするのですがこれくらいなら使える程度の速さで使用できます。
ただ、今回の紹介したやりかたで50行以上つくるとスクレイピングする時間がかかる場合があります。ちょっと一覧表を作って使う程度の場合簡単にサイト情報を表にできるのでおすすめです。

